
glm-5-turbo
GLM-5-Turbo 是面向 OpenClaw 龙虾场景深度优化的基座模型
2026-03-16


输入:
$0.72/1M tokens起
输出:
$3.2/1M tokens起
大额采购联系客户经理享专属优惠
稳定性
稳定
API介绍
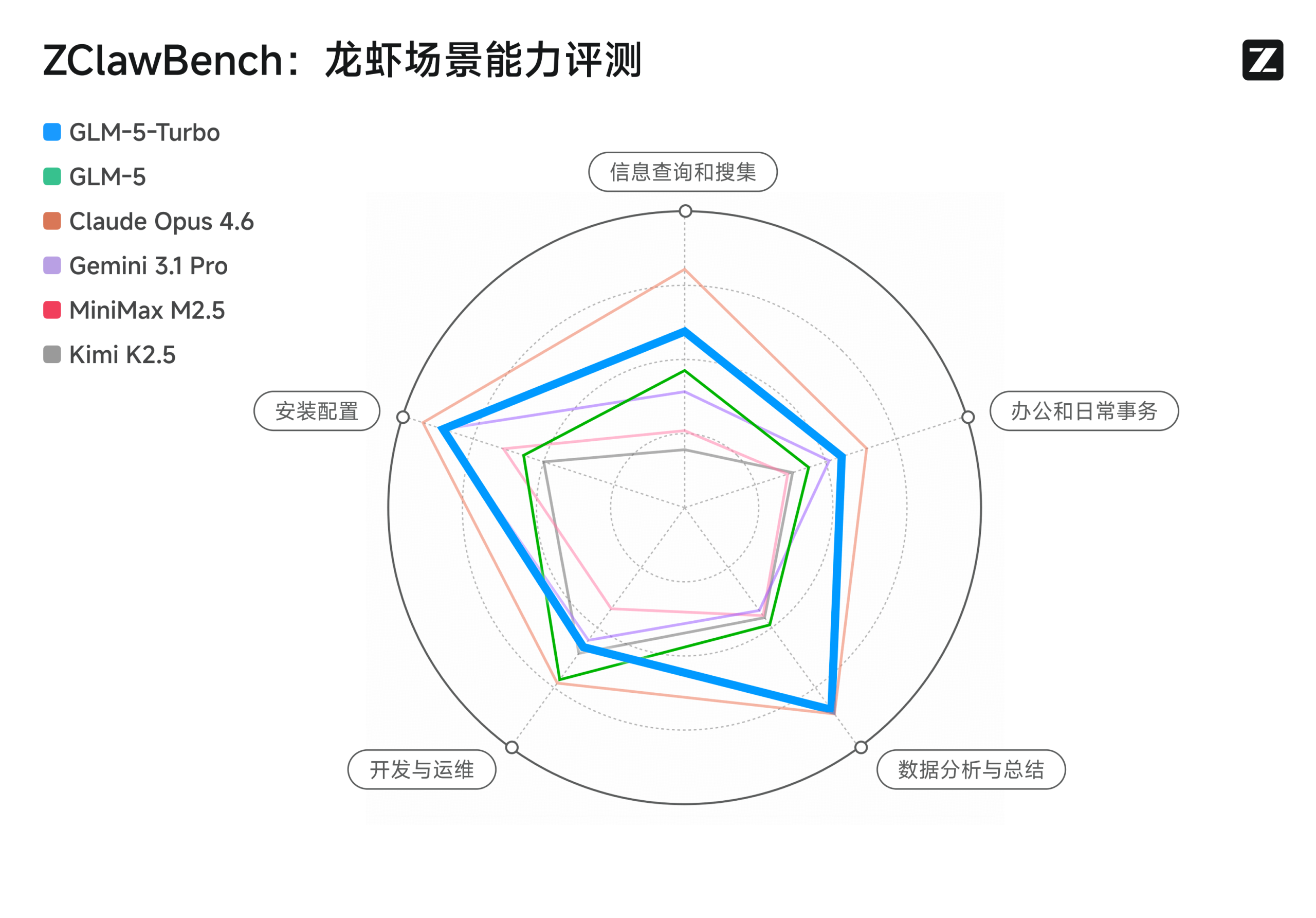
GLM-5-Turbo 是基于 GLM-5 旗舰模型打造的高性能优化版本,专为追求“极速推理”与“高频 Agent 执行”的业务场景而生。它在保持 GLM-5 原有的长逻辑推理与系统工程能力的同时,通过架构优化实现了推理速度的显著提升,是构建自动化 Agent 工作流、高响应实时交互应用及大规模编程协作任务的最佳选择。
───────────────────────────────────────────────────────────────────
核心能力
极致推理速度: 针对 Agentic(智能体)调用场景进行了深度提速优化,大幅降低了推理延迟,确保 AI 在多步执行任务时能做到“快如闪电”。
Agent 工作流专属优化: 专门优化了对工具调用(Tool Use)和多阶段长周期任务的响应效率,完美适配如 OpenClaw 等智能体编排框架,实现复杂任务的秒级反馈。
性价比领先: 以更小的资源开销实现了接近 GLM-5 的处理性能,非常适合在保证业务质量前提下,实现大规模 AI 自动化业务的成本管控。
编程协作的加速器: 在 Claude Code、OpenCode 等编码 Agent 应用中,它能够显著提升代码生成与调试的迭代效率,是开发者提升编码生产力的利器。
 ───────────────────────────────────────────────────────────────────
───────────────────────────────────────────────────────────────────
相关测评
《GLM-5-Turbo 实测:抛弃花哨的思考,只做最硬核的执行》

Playground
登录后,探索更多精彩功能! 点击登录
API统计
API列表 (1)
API价格表
$¥ 円 ₽