
zai-org/glm-4.7-flash
智谱AI推出的GLM-4.7系列的高效版语言模型,兼顾性能与效率
2026-01-23


输入:
$0.0715/1M tokens
输出:
$0.429/1M tokens
大额采购联系客户经理享专属优惠
稳定性
稳定
API介绍
GLM-4.7-Flash 是智谱AI推出的免费级高性能文本语言模型,核心定位为“在 30B 级别实现 SOTA 性能与高效率平衡的轻旗舰”,面向 Agentic Coding、深度研究与高频协作场景提供强大支持。
- 升级点:作为 GLM-4.7 系列的高效版本,在 SWE-bench Verified、τ²-Bench 等基准中取得同尺寸开源模型领先表现
- 适用场景:Agentic Coding(端到端可运行代码生成)、Deep Research(多源信息整合)、前端/PPT 自动生成、角色扮演创作、智能客服等
- 产品价值:支持 200K 上下文与 128K 输出,复杂任务开发与部署成本显著降低
- 能力强化:编码能力大幅增强,可自主完成需求拆解、多技术栈整合;前端审美优化,PPT/网页生成更接近“即用级”
- 交互体验:多轮对话中稳定保持上下文,对复杂问题持续澄清目标,更像一名“问题解决型伙伴”
───────────────────────────────────────────────────────────────────
核心能力
⚡ 长上下文高效处理:200K 输入窗口 + 智能上下文缓存,长对话不卡顿、不遗忘
🧠 深度思考模式:支持启用 thinking 模式,实现“先思考、再行动”的推理链,提升复杂任务准确性
🛠️ 强大工具协同:原生支持 Function Call 与 MCP 协议,可灵活调用外部工具与数据源
🎨 前端审美升级:布局、配色、组件样式更具美感,默认方案减少反复微调成本
📊 结构化输出:支持 JSON 等格式,便于系统直接解析,无缝集成至自动化流程
💬 流式实时响应:支持流式输出,逐字返回结果,打造低延迟、高沉浸的交互体验
───────────────────────────────────────────────────────────────────
测试数据
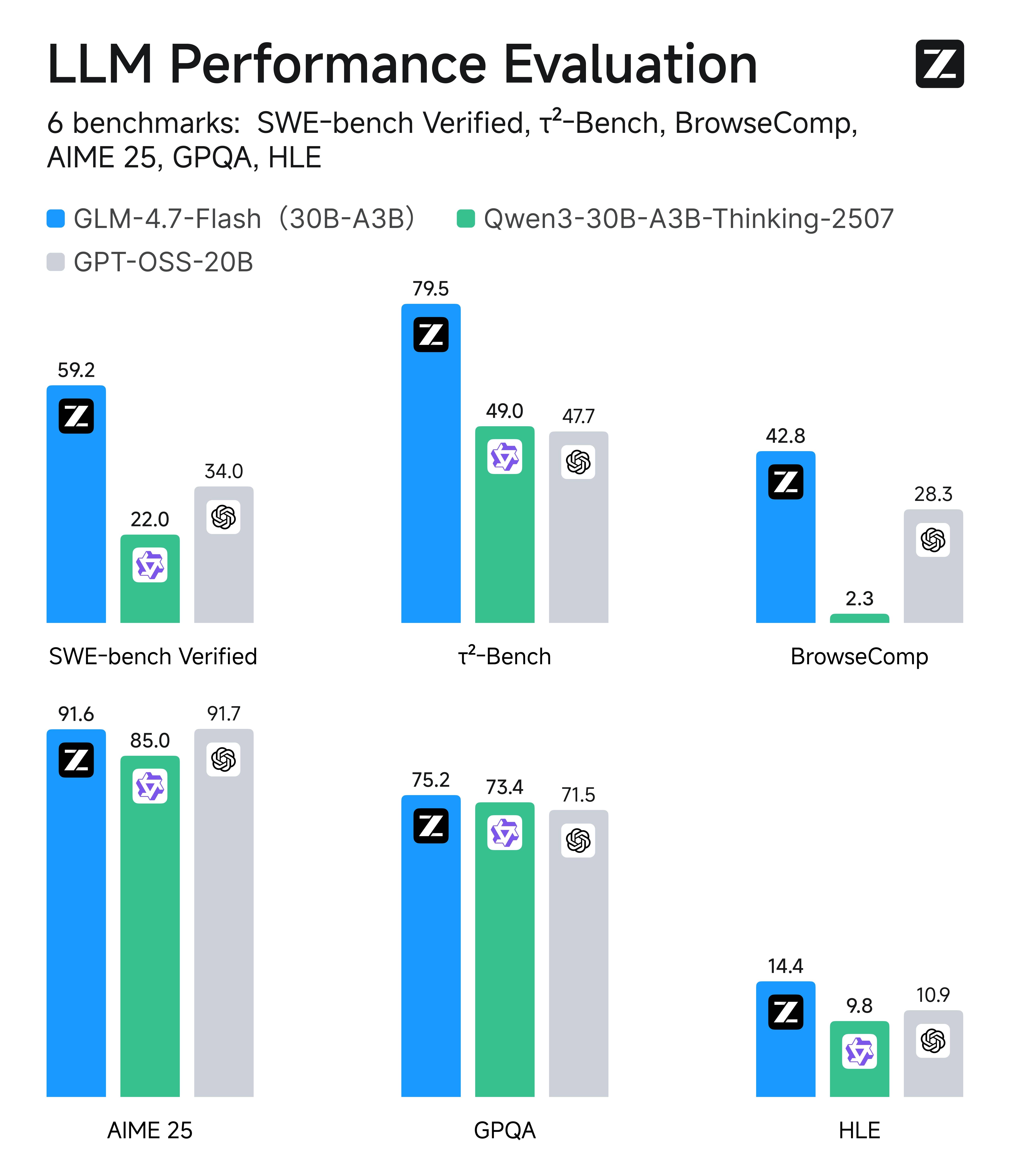
- 在 SWE-bench Verified、τ²-Bench 等主流基准测试中,GLM-4.7-Flash 达到同尺寸开源模型的 SOTA 水平。
- 具备领先的前端与后端开发能力,在内部编程实测中表现优异。
- 通用能力强,推荐用于中文写作、翻译、长文本处理、情感表达及角色扮演等场景。
Playground
登录后,探索更多精彩功能! 点击登录
API统计
API列表 (1)
API价格表
$¥ 円 ₽