
qwen/qwen3-coder-480b-a35b-instruct
阿里巴巴推出的4800亿参数级 MoE 编码模型,专为复杂软件工程任务设计。
2025-07-23

输入:
$2.14/1M tokens
输出:
$2.14/1M tokens
大额采购联系客户经理享专属优惠
API介绍
Qwen3-Coder-480B-A35B-Instruct 是阿里巴巴推出的4800亿参数级 MoE 编码模型,核心定位为全球最强开源编程智能体(Agentic Coding)基座,原生支持 256K 上下文(扩展至 1M),专为复杂软件工程任务设计。
- 性能登顶:在 SWE-bench Verified(69.6%)、WebArena(49.9%)等 12 项评测中刷新开源模型纪录,综合性能比肩 Claude Sonnet 4。
- 超长理解:原生支持 256K tokens 上下文,通过 YaRN 技术可扩展至 100 万 tokens,轻松处理整仓库代码分析。
- 双模式切换:独创“思考模式”与“非思考模式”,动态平衡响应速度(亚秒级)与深度推理(多轮规划)。
- 全栈工具链:配套开源命令行工具 Qwen Code(兼容 OpenAI SDK),并支持 Claude Code、Cline 等主流 IDE 无缝接入。
- 极致性价比:通过 FP8 量化与 MoE 动态激活(仅 35B 参数实时运算),推理成本降低 60%,API 调用低至 0.8 元/百万 tokens。
───────────────────────────────────────────────────────────────────
核心能力
🤖 智能体编程:自主完成需求分析、代码生成、工具调用与调试全流程,实测 500 轮交互下修复 GitHub issue 成功率达 69.6%。
🌐 跨语言专家:深度掌握 Python、Java、C++ 等 20+ 语言,在 Aider-Polyglot 多语言编程测试中以 61.8 分居开源榜首。
⚡ MoE 极速引擎:4800 亿参数海纳百川,推理时仅激活 350 亿参数,实现高性能与低延迟的完美解耦(RTX 4090 响应 <500ms)。
🔧 生态零摩擦:原生适配 VS Code、PyCharm 等工具,通过 qwen! 指令一键启动智能编程,支持私有化部署与企业级安全合规。
───────────────────────────────────────────────────────────────────
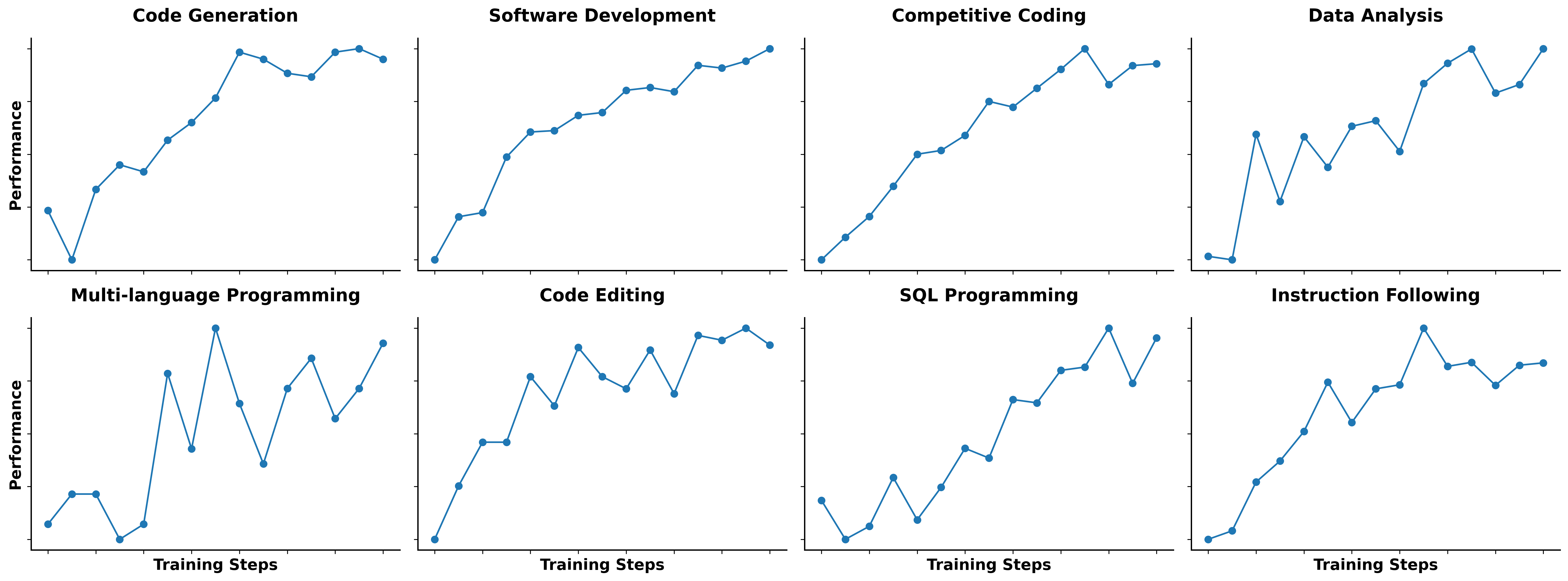
测试数据
Playground
登录后,探索更多精彩功能! 点击登录
API统计
API列表 (1)
API价格表
$¥ 円 ₽